Example Usage
Basics
In this section we show how to submit an audio file for batch transcription. We show how to poll for the status of a job, and to return a transcript once the job is done. Later on we show an alternate method of retrieving the transcript using a webhook-based notification.
Submitting a Job
Speechmatics Cloud Offering Demo: Post Job Request
The simplest configuration for a transcription job is simply to specify the language that you wish to use. This is encoded in the language property of the transcription configuration like this:
Unix/Ubuntu
curl -L -X POST 'https://asr.api.speechmatics.com/v2/jobs' \
-H 'Authorization: Bearer NDFjOTE3NGEtOWVm' \
-F data_file=@example.wav \
-F config='{
"type": "transcription",
"transcription_config": { "language": "en" }
}' \
| jq
Windows
curl -L -X POST "https://asr.api.speechmatics.com/v2/jobs" ^
-H "Authorization: Bearer NDFjOTE3NGEtOWVm" ^
-F data_file=@example.wav ^
-F config='{
"type": "transcription",
"transcription_config": { "language": "en" }
}'\
| jq
Here NDFjOTE3NGEtOWVm is a sample authorization token. You would replace this with the token that you have been provided with.
[info] model parameter
The
modelform parameter in V1 is replaced with thelanguageelement oftranscription_config
The JSON response that you see will contain the unique Job ID. For full details see the Jobs API Reference. An example response will look like this:
HTTP/1.1 201 Created
Content-Length: 20
Content-Type: application/json
Request-Id: 4d46aa73e1a4c5a6d4ba6c31369e7b2e
Strict-Transport-Security: max-age=15724800; includeSubDomains
X-Azure-Ref: 0XdIUXQAAAADlflaR0qvRQpReZYf+q+FHTE9OMjFFREdFMDMwNwBhN2JjOWQ4MC02YjBiLTQ1NWEtYjE3MS01NGJkZmNiYWE0YTk=
Date: Thu, 27 Jun 2019 14:27:45 GMT
{"id":"dlhsd8d69i"}
[info] model parameter
The
200 OKstatus code in V1 is replaced with a201 Createdstatus code in V2. This indicates that the job has been accepted for processing; it does not necessarily mean that the job will complete successfully.
The Request-ID unqiuely identifies your API request. If you ever need to raise a support ticket we recommend that you include the Request-ID if possible, as it will help to identify your job. The Strict-Transport-Security response header indicates that only HTTPS access is allowed. The X-Azure-Ref response header identifies the load-balancer request.
If you do not specify an auth token in the request, or if the token provided is invalid, then you'll see a 401 status code like this:
HTTP/1.1 401 Authorization Required
[info] Maximum job size
The size limit for jobs is 12 hours of audio or 1 GB file size. For example, if you submit a file that is 1.2 GB in size, or 13 hours in length then it may get rejected. You can use tools like
soxorffmpegto break up large audio files. If you require additional help or have a need for submission of larger files, please contact support@speechmatics.com.
Checking Job Status
A 201 Created status indicates that the job was accepted for processing. To check that the job is being processed you can check to see where it is in the processing pipeline as follows:
Unix/Ubuntu
curl -L -X GET 'https://asr.api.speechmatics.com/v2/jobs/yjbmf9kqub' \
-H 'Authorization: Bearer NDFjOTE3NGEtOWVm' \
| jq
Windows
curl -L -X GET "https://asr.api.speechmatics.com/v2/jobs/yjbmf9kqub" ^
-H "Authorization: Bearer NDFjOTE3NGEtOWVm" | jq
The response is a JSON object containing details of the job, with the status field showing whether the job is still processing or not. A value of done means that the transcript is now ready. Jobs will typically take less than half the audio length to process; so an audio file that is 40 minutes in length should be ready within 20 minutes of submission. See Jobs API Reference for details. An example response looks like this:
HTTP/1.1 200 OK
Content-Type: application/json
{
"job": {
"config": {
"notification_config": null,
"transcription_config": {
"additional_vocab": null,
"channel_diarization_labels": null,
"language": "en"
},
"type": "transcription"
},
"created_at": "2019-01-17T17:50:54.113Z",
"data_name": "example.wav",
"duration": 275,
"id": "yjbmf9kqub",
"status": "running"
}
}
Possible job status types include:
- running
- done
- rejected
- deleted
- expired
[info] Alignment jobs
Alignment is not supported with the V2 API. Speechmatics supports alignment jobs only on the V1 API.
Retrieving a Transcript
Speechmatics Cloud Offering Demo: Retrieving Transcripts
Transcripts can be retrieved as follows:
Unix/Ubuntu
curl -L -X GET 'https://asr.api.speechmatics.com/v2/jobs/yjbmf9kqub/transcript' \
-H 'Authorization: Bearer NDFjOTE3NGEtOWVm' | jq
Windows
curl -L -X GET 'https://asr.api.speechmatics.com/v2/jobs/yjbmf9kqub/transcript' ^
-H 'Authorization: Bearer NDFjOTE3NGEtOWVm' | jq
The supported formats are json-v2 (default), srt (SubRip subtitle format) and txt (plain text). The format is set using the format query string parameter, for example:
Unix/Ubuntu
curl -L -X GET 'https://asr.api.speechmatics.com/v2/jobs/yjbmf9kqub/transcript?format=txt' \
-H 'Authorization: Bearer NDFjOTE3NGEtOWVm'
Windows
curl -L -X GET "https://asr.api.speechmatics.com/v2/jobs/yjbmf9kqub/transcript?format=txt" ^
-H "Authorization: Bearer NDFjOTE3NGEtOWVm"
See Jobs API Reference for details.
[info] Legacy JSON output format
The current
jsonoutput format for the V1 API is considered legacy as it does not support the new features like Channel Diarization as well as allowing future feature expansion. Speechmatics recommends that you use the json-v2 output format to take advantage of new features.
The job property contains information about the job such as the job ID and duration.
The metadata property contains whatever tracking information was included when the job was submitted, as well as the configuration that was used to submit the job.
The results section which is an array of words comprising the actual transcript. An example transcript using the JSON output format is shown:
HTTP/1.1 200 OK
Transfer-Encoding: chunked
Content-Type: application/vnd.speechmatics.v2+json
Request-Id: aad4eb68bca69f3f277d202456bb0b15
Strict-Transport-Security: max-age=15724800; includeSubDomains
X-Azure-Ref: 0ztQUXQAAAAA4ifGtw2COQKyb52QoNgX4TE9OMjFFREdFMDMyMABhN2JjOWQ4MC02YjBiLTQ1NWEtYjE3MS01NGJkZmNiYWE0YTk=
Date: Thu, 27 Jun 2019 14:38:05 GMT
{
"format":"2.4",
"job":{
"created_at":"2019-01-17T17:50:54.113Z",
"data_name":"example.wav",
"duration":275,
"id":"yjbmf9kqub"
},
"metadata":{
"created_at":"2019-01-17T17:52:26.222Z",
"transcription_config":{
"diarization":"none",
"language":"en"
},
"type":"transcription"
},
"results":[
{
"alternatives":[
{
"confidence":0.9,
"content":"Just",
"language":"en",
"speaker":"UU"
}
],
"end_time":1.07,
"start_time":0.9,
"type":"word"
},
{
"alternatives":[
{
"confidence":1,
"content":"this",
"language":"en",
"speaker":"UU"
}
],
"end_time":1.44,
"start_time":1.11,
"type":"word"
},
{
"alternatives":[
{
"confidence":1,
"content":".",
"language":"en",
"speaker":"UU"
}
],
"end_time":273.64,
"start_time":273.64,
"type":"punctuation"
}
]
}
[warning] use of non-ASCII output
You should be aware that for most non-English languages, you will be working with characters outside the ASCII range. Ensure that the programming language or client framework you are using is able to output the human-readable or machine-readable format that you require for your use case. Some client bindings will assume that non-ASCII characters are escaped, others do not. In most cases there will be a parameter that enables you to decide which you want to output.
[info] created_at timestamps
There are two
created_attimestamps, one in the job section which indicates when the job was submitted and another in the metadata section which indicates when the output was produced. The time difference provides the transcription time, including any system delays as well as the actual time taken to process the job.
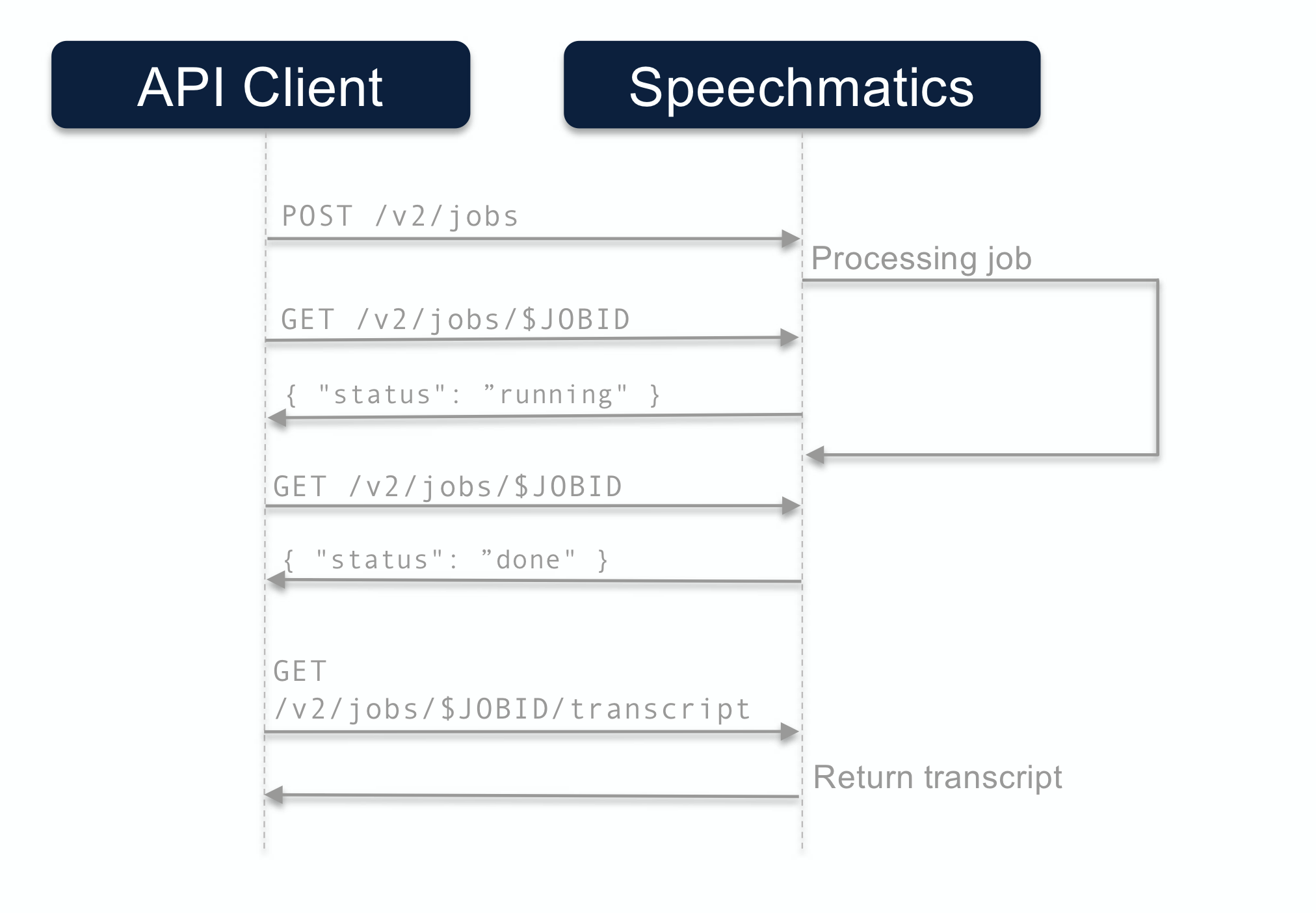
Polling Call Flow
The call flow for the polling method looks like this:
Fetch URL
Speechmatics Cloud Offering Demo: Fetch URL Callback
The previous example showed how to create a job from a locally uploaded audio file. If you store your digital media in cloud storage (for example AWS S3 or Azure Blob Storage) you can also submit a job by providing the URL of the audio file. The configuration uses a fetch_data section, which looks like this:
Unix/Ubuntu
curl -L -X POST 'https://asr.api.speechmatics.com/v2/jobs' \
-H 'Authorization: Bearer NDFjOTE3NGEtOWVm' \
-F config='{
"type": "transcription",
"transcription_config": { "language": "en" },
"fetch_data": { "url": "https://s3.us-east-2.amazonaws.com/bucketname/jqld_/20180804102000/profile.m4v" }
}' \
| jq
Windows
curl -L -X POST 'https://asr.api.speechmatics.com/v2/jobs' ^
-H 'Authorization: Bearer NDFjOTE3NGEtOWVm' ^
-F config='{
"type": "transcription",
"transcription_config": { "language": "en" },
"fetch_data": { "url": "https://s3.us-east-2.amazonaws.com/bucketname/jqld_/20180804102000/profile.m4v" }
}' \
| jq
Some cloud storage solutions may require authentication. You can use the auth_headers property in the fetch_data section to provide the headers necessary to access the resource.
Notifications
The method described in the previous section assumes that polling is used to check on the status of the job, before making the call to retrieve the transcript. A more convenient method is to use notifications. This involves a callback to a web service that you control. An HTTP POST is then made from the Speechmatics service to your web server once the transcript is available.
The notification support offered in V1 has been extended and generalized in V2 to support a wider range of customer integration scenarios:
- A callback can be configured to not include any data attachments, so it can be used as a lightweight signal that results are ready to be fetched through the normal API without needing to poll.
- Multiple pieces of content can be sent as multiple attachments in one request, allowing any combination of the input(s) and output(s) of the job to be forwarded to another processing stage. Formatting options for outputs can be specified per attachment. The full details of the job are available as a content item, as well as being included in the json-v2 transcript format.
- You can setup multiple notifications to different endpoints: for instance you can send a jobinfo notificaiton to one service, and the transcript notification to another.
- Callbacks with a single attachment will send the content item as the HTTP request body, rather than using multipart mode. This allows writing an individual item to an object store like Amazon S3.
- HTTP PUT methods are now supported to allow uploading of content directly to an object store such as S3.
- A set of additional HTTP request headers can be specified:
- To satisfy authentication / authorization requirements for systems that do not support auth tokens in query parameters.
- To control behaviour of an object store or another existing service endpoint.
- Multiple callbacks can be specified per job.
- This allows sending individual pieces of content to different URLs, eg. to allow uploading the audio and transcript to an object store as distinct objects for a downstream workflow.
- It allows sending arbitrary combinations of the inputs/outputs to multiple destinations, to support a fanout workflow.
Callbacks will be invoked in parallel and so may complete in any order. If a downstream workflow depends on getting several items of content delivered as separate callbacks (eg. uploaded as separate items to S3), then the downstream processing logic will need to be robust to the ordering of uploads and the possibility that only some might succeed.
To ensure that the callbacks you receive come from Speechmatics you can apply a whitelist.
[info] Email notification
Email notification is not currently supported.
Configuring the Callback
The callback is specified at job submission time using the notification_config config object. For example:
Unix/Ubuntu
curl -L -X POST 'https://asr.api.speechmatics.com/v2/jobs' \
-H 'Authorization: Bearer NDFjOTE3NGEtOWVm' \
--form data_file=@example.wav \
--form config='{
"type": "transcription",
"transcription_config": { "language": "en" },
"notification_config": [
{
"url": "https://collector.example.org/callback",
"contents": [ "transcript", "data" ],
"auth_headers": [
"Authorization: Bearer eyJ0eXAiOiJKV1QiLCJhb"
]
}
]
}' \
| jq
Windows
curl -L -X POST "https://asr.api.speechmatics.com/v2/jobs" ^
-H "Authorization: Bearer NDFjOTE3NGEtOWVm" ^
--form data_file=@example.wav ^
--form config='{
"type": "transcription",
"transcription_config": { "language": "en" },
"notification_config": [
{
"url": "https://collector.example.org/callback",
"contents": [ "transcript", "data" ],
"auth_headers": [
"Authorization: Bearer eyJ0eXAiOiJKV1QiLCJhb"
]
}
]
}' \
| jq
This example assumes you have implemented a /callback endpoint on host collector.example.org that listens for POST requests containing Speechmatics transcripts. In this example requests are only accepted if the auth token eyJ0eXAiOiJKV1QiLCJhb is used (note this is the auth token that your service accepts, not the Speechmatics auth token).
Accepting the Callback
You need to ensure that the service that you implement to receive the callback notification is capable of processing the Speechmatics transcript using the format that has been specified in the config JSON. When testing your integration you should check the error logs on your web service to ensure that notifications are being accepted and processed correclty.
The callback appends the job ID as a query string parameter with name id, as well as the status of the job. As an example, if the job ID is r6sr3jlzjj, you'd see the following POST request:
POST /callback?id=r6sr3jlzjj&status=success HTTP/1.1
Host: collector.example.org
The user agent is Speechmatics-API/2.0.
Notification Call Flow
The call flow for the notification method looks like this:
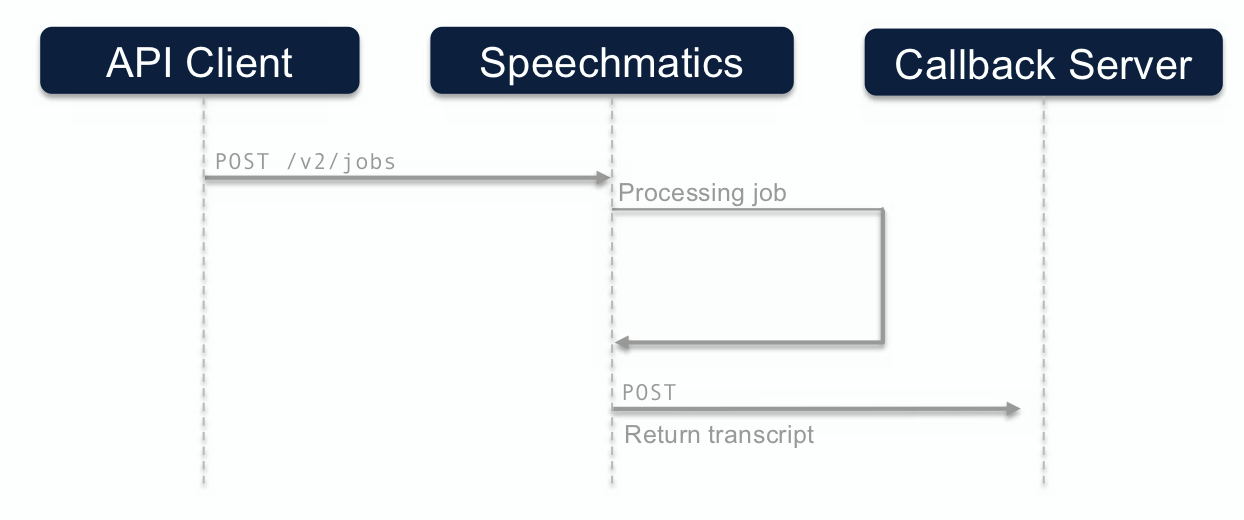
Callback webserver configuration
Once the submitted media file is transcribed by the Speechmatics cloud and the transcript file is available, the Speechmatics cloud service will send the transcript file in a HTTP POST request to the client web server (customers webserver) specified in the notification_config config object. If the Speechmatics cloud service does not receive a 2xx response (that the request is successfully received, understood, or accepted) it will keep trying to send the file until it reaches the set timeout threshold.
If the clients webserver that has been set as the callback endpoint is not configured with a large enough size limit to receive the transcript file and original media file it will generate a 413 (Request Entity Too Large) response to the Speechmatics service. The Speechmatics cloud service app has not receive a 2xx response it will continue to retry sending the file.
Users are recommended to check their webserver size limits to ensure they are adequate for the files that will be sent.
Speaker Diarization
Diarization is a way of dividing up an input stream into marked segments according to speaker identity. Diarization can be set via the config object by setting the diarization property to speaker:
"transcription_config": {
"language": "en",
"diarization": "speaker"
}
Channel Diarization
The V2 API also supports Channel Diarization which can be used to add your own speaker or channel labels to the transcript. With Channel Diarization, multiple input channels are processed individually and collated into a single transcript. In order to use this method of diarization your input audio must have been transcoded into multiple channels or streams.
In order to use this feature you set the diarization property to channel and (optionally) specify the channel_diarization_labels:
"transcription_config": {
"language": "en",
"diarization": "channel",
"channel_diarization_labels": [
"Presenter",
"Questions"
]
}
If you do not specify any labels then defaults will be used. The number of labels you use should be the same as the number of channels in your audio. Additional labels are ignored. When the transcript is returned a channel property for each word will indicate the speaker, for example:
"results": [
{
"type": "word",
"end_time": 1.8,
"start_time": 1.45,
"channel": "Presenter"
"alternatives": [
{
"display": { "direction": "ltr" },
"language": "en",
"content": "world",
"confidence": 0.76
}
]
}
]
Speaker Change Detection
This feature introduces markers into the transcript that indicate when a speaker change has been detected in the audio. For example, if the audio contains two people speaking to each other and you want the transcript to show when there is a change of speaker, specify speaker_change as the diarization setting:
{"type": "transcription",
"transcription_config": {
"diarization": "speaker_change"
}
}
The transcript will have special json elements in the results array between two words where a different person started talking. For example, if one person says "Hello James" and the other responds with "Hi", there will a speaker_change json element between "James" and "Hi".
{
"format": "2.4",
"job": {
....
},
"metadata": {
....
},
"results": [
{
"start_time": 0.1,
"end_time": 0.22,
"type": "word",
"alternatives": [
{
"confidence": 0.71,
"content": "Hello",
"language": "en",
"speaker": "UU"
}
]
},
{
"start_time": 0.22,
"end_time": 0.55,
"type": "word",
"alternatives": [
{
"confidence": 0.71,
"content": "James",
"language": "en",
"speaker": "UU"
}
]
},
{
"start_time": 0.55,
"end_time": 0.55,
"type": "speaker_change",
"alternatives": []
},
{
"start_time": 0.56,
"end_time": 0.61,
"type": "word",
"alternatives": [
{
"confidence": 0.71,
"content": "Hi",
"language": "en",
"speaker": "UU"
}
]
}
]
}
The sensitivity of the speaker change detection is set to a sensible default that gives the optimum performance under most circumstances. You can however change this if you with using the speaker_change_sensitivity setting, which takes a value between 0 and 1 (the default is 0.4). The higher the sensitivity setting, the more liklihood of a speaker change being indicated. We've found through our own experimentation that values outside the range 0.3-0.6 produce too few speaker change events, or too many false positives. Here's an example of how to set the value:
{"type": "transcription",
"transcription_config": {
"diarization": "speaker_change",
"speaker_change_sensitivity": 0.55
}
}
Speaker Change Detection With Channel Diarization
The speaker change feature can be used in conjunction with channel diarization. It will process the channels separately and indicate in the output both the channels and the speaker changes. For example, if a two-channel audio contains two people greeting each other (both recorded over the same channel), the config submitted with the audio can request speaker change detection like this:
{"type": "transcription",
"transcription_config": {
"diarization": "channel_and_speaker_change"
}
}
Again, the speaker_change_sensitivity setting may be used to tune the liklihood of speaker change being identified.
Custom Dictionary
The Custom Dictionary feature can be accessed through the additional_vocab property. This is a list of custom words or phrases that should be recognized. Custom Dictionary Sounds is an extension to this to allow alternative pronunciations to be specified in order to aid recognition, or provide for alternative transcriptions:
"transcription_config": {
"language": "en",
"additional_vocab": [
{
"content": "gnocchi",
"sounds_like": [
"nyohki",
"nokey",
"nochi"
]
},
{
"content": "CEO",
"sounds_like": [
"C.E.O."
]
},
{ "content": "financial crisis" }
]
}
You can specify up to 1000 words or phrases (per job) in your custom dictionary.
In the above example, the words gnocchi and CEO have pronunciations applied to them; the phrase financial crisis does not require a pronunciation. The content property represents how you want the word to be output in the transcript. This allows you to implement a simple profanity filter for example by using the content property to replace redacted words with "*" for instance.
Output Locale
It is possible to specify the spelling rules to be used when generating the transcription, based on locale. The output_locale configuration setting is used for this. As an example, the following configuration uses the Global English (en) language pack with an output locale of British English (en-GB):
{ "type": "transcription",
"transcription_config": {
"language": "en",
"output_locale": "en-GB"
}
}
Currently, Global English (en) is the only language pack that supports different output locales. The three locales that are available in this release are:
- British English (en-GB)
- US English (en-US)
- Australian English (en-AU)
If no locale is specified then the ASR engine will use whatever spelling it has learnt as part of our language model training (in other words it will be based on the training data used).
Advanced Punctuation
Some language models (English, French, German and Spanish currently) now support advanced punctuation. This uses machine learning techniques to add in more naturalistic punctuation to make the transcript more readable. As well as putting punctuation marks in more naturalistic positions in the output, additional punctuation marks such as commas (,) and exclamation and question marks (!, ?) will also appear.
There is no need to explicitly enable this in the job configuration; languages that support advanced punctuation will automatically output these marks. If you do not want to see these punctuation marks in the output, then you can explicitly control this through the punctuation_overrides settings in the config.json file, for example:
"transcription_config": {
"language": "en",
"punctuation_overrides": {
"permitted_marks":[ ".", "," ]
}
}
Both plain text and JSON output supports punctuation. JSON output places punctuation marks in the results list marked with a type of "punctuation". So you can also filter on the output if you want to modify or remove punctuation.
If you specify the punctuation_overrides element for lanuguages that do not yet support advanced punctuation then it is ignored.
Metadata and Job Tracking
It is now possible to attach richer metadata to a job using the tracking configuration. The tracking object contains the following properties:
| Name | Type | Description | Notes |
|---|---|---|---|
| title | str | The title of the job. | [optional] |
| reference | str | External system reference. | [optional] |
| tags | list[str] | [optional] | |
| details | object | Customer-defined JSON structure. | [optional] |
This allows you to track the job through your own management workflow using whatever information is relevant to you.
Unix/Ubuntu
curl -L -X POST 'https://asr.api.speechmatics.com/v2/jobs' \
-H 'Authorization: Bearer NDFjOTE3NGEtOWVm' \
--form data_file=@example.wav \
--form config='{
"type": "transcription",
"transcription_config": { "language": "en" },
"tracking": {
"title": "ACME Q12018 Statement",
"reference": "/data/clients/ACME/statements/segs/2018Q1-seg8",
"tags": [ "quick-review", "segment" ],
"details": {
"client": "ACME Corp",
"segment": 8,
"seg_start": 963.201,
"seg_end": 1091.481
}
}
}' \
| jq
Windows
curl -L -X POST "https://asr.api.speechmatics.com/v2/jobs" ^
-H "Authorization: Bearer NDFjOTE3NGEtOWVm" ^
--form data_file=@example.wav ^
--form config='{
"type": "transcription",
"transcription_config": { "language": "en" },
"tracking": {
"title": "ACME Q12018 Statement",
"reference": "/data/clients/ACME/statements/segs/2018Q1-seg8",
"tags": [ "quick-review", "segment" ],
"details": {
"client": "ACME Corp",
"segment": 8,
"seg_start": 963.201,
"seg_end": 1091.481
}
}
}' \
| jq
Deleting a Job
The current retention period for jobs is 7 days; after this time jobs are removed. If you wish to save jobs you should import them into your own data store before they are removed.
You can remove jobs yourself once you no longer require them by explicitly deleting a job as follows:
Unix/Ubuntu
curl -L -X DELETE 'https://asr.api.speechmatics.com/v2/jobs/yjbmf9kqub' \
-H 'Authorization: Bearer NDFjOTE3NGEtOWVm' | jq
Windows
curl -L -X DELETE "https://asr.api.speechmatics.com/v2/jobs/yjbmf9kqub" ^
-H "Authorization: Bearer NDFjOTE3NGEtOWVm" | jq